

AI検索やRAG(検索拡張生成)の文脈で「スパースベクトル」という言葉を耳にする機会が増えています。密ベクトル(dense vector)との違いや、なぜ稀な語や専門用語に強いのかが分かりにくいと感じる方も多いのではないでしょうか。この記事では、スパースベクトルの基本概念からAI検索における活用方法、密ベクトルとの違い、そしてハイブリッド検索による使い分けまでを、非専門家にも分かりやすく整理します。読み終えるころには、自社のAI検索やRAG設計に対する判断軸が得られるはずです。
- スパースベクトルと密ベクトルの違い
スパースベクトルは「ほとんどが0で一部だけ値が入る」表現で語彙レベルの精密な一致に強く、密ベクトルは意味的類似性に強いという特徴があります。
- AI検索でスパースベクトルが果たす役割
BM25などの古典的手法を進化させたニューラルスパースモデルが登場し、レア語や専門用語に強く説明可能性も高い検索を実現します。
- ハイブリッド検索による使い分けの指針
スパースと密ベクトルを組み合わせることで、語彙一致と意味理解の両立が可能になり、RAGや社内検索など実務での精度向上に寄与します。
スパースベクトルとは何か
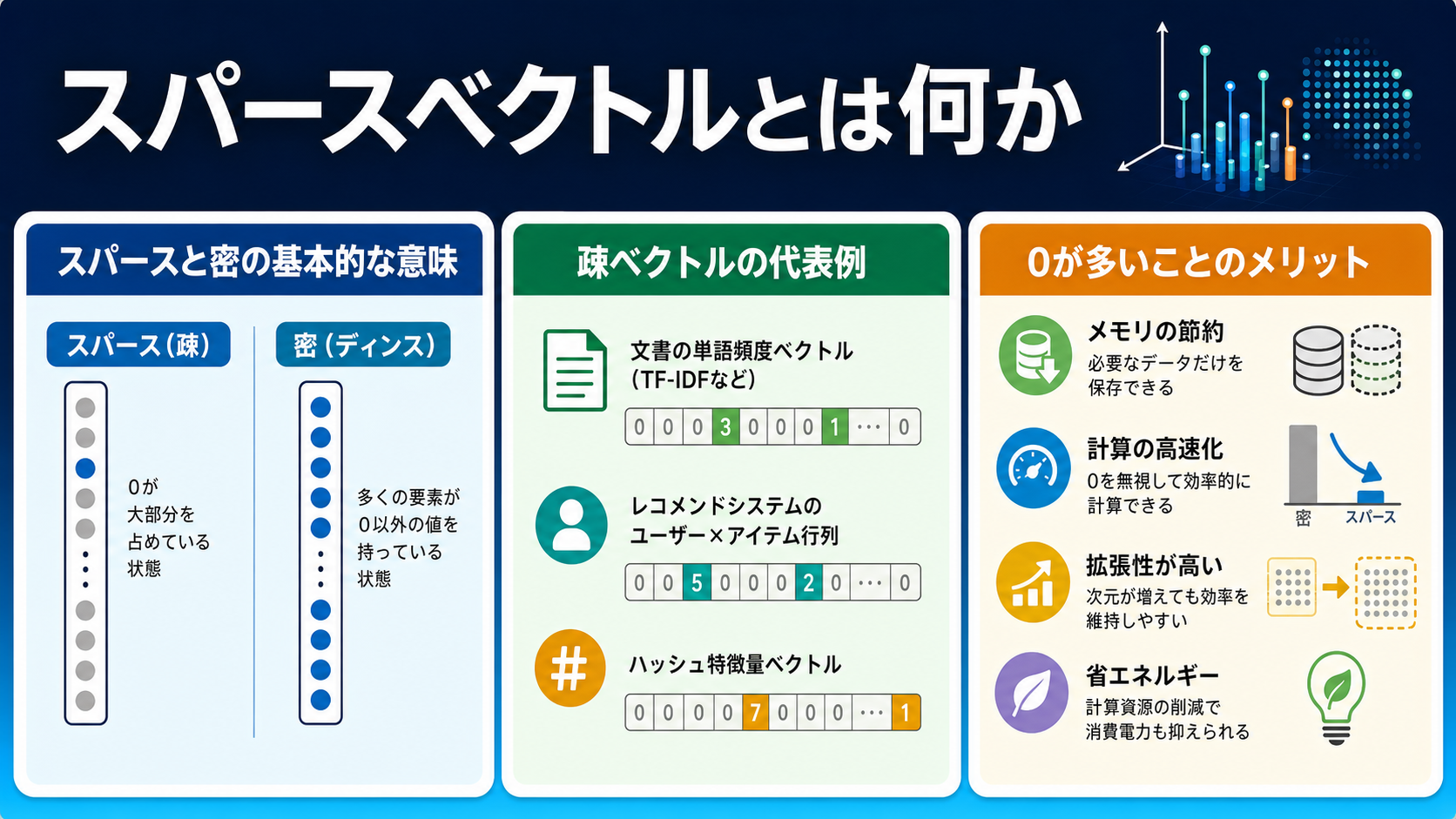
スパースと密の基本的な意味
スパースベクトルは「巨大なチェックリストの中で、チェックが付いている項目だけが意味を持つ」イメージで捉えると直感的に理解しやすくなります。たとえば日本語の語彙が10万語あるとすれば、1つの文書を10万次元のベクトルで表現し、その文書に出てくる単語の次元にだけ値が入る形になります。
一方、密ベクトルは数百〜数千次元の比較的小さな空間に、すべての次元に何らかの値が詰まっている表現です。両者は次元数の大小だけでなく、情報の持ち方そのものが根本的に異なります。
疎ベクトルの代表例
古典的な疎ベクトルの代表例として、Bag-of-Words、TF-IDF、BM25スコアなどが挙げられます。これらはいずれも「文書に登場する単語」と「その重み」をベクトル化したもので、語彙の数だけ次元を持ちます。
たとえばTF-IDFでは、文書内での単語の出現頻度と、コーパス全体での希少性を掛け合わせた値が各次元に入ります。BM25はこれをさらに改良したもので、現在も検索エンジンの中核技術として広く使われています。
0が多いことのメリット
ベクトルの大半が0であることには、計算上の大きな利点があります。非ゼロの要素だけをインデックスに保存できるため、ストレージ効率が高く、転置インデックスとの相性も抜群です。
また、検索時はクエリに含まれる単語の次元だけを参照すればよいため、高速な類似度計算が可能になります。これがスパースベクトル検索の性能上の優位性の源泉です。
| 項目 | スパースベクトル | 密ベクトル |
|---|---|---|
| 次元数 | 数万〜数十万 | 数百〜数千 |
| 非ゼロ要素 | ごく一部 | ほぼすべて |
| 意味の単位 | 語彙(単語・トークン) | 抽象的な特徴 |
| 説明可能性 | 高い | 低い |
この表からも分かるように、スパースと密はトレードオフの関係にあり、用途に応じた選択が必要です。

スパースベクトルは「0が多いほどうれしい」という独特な世界観なんです。まずは語彙ベースの表現というイメージを押さえておきましょう。
AI検索とスパースベクトルの関係
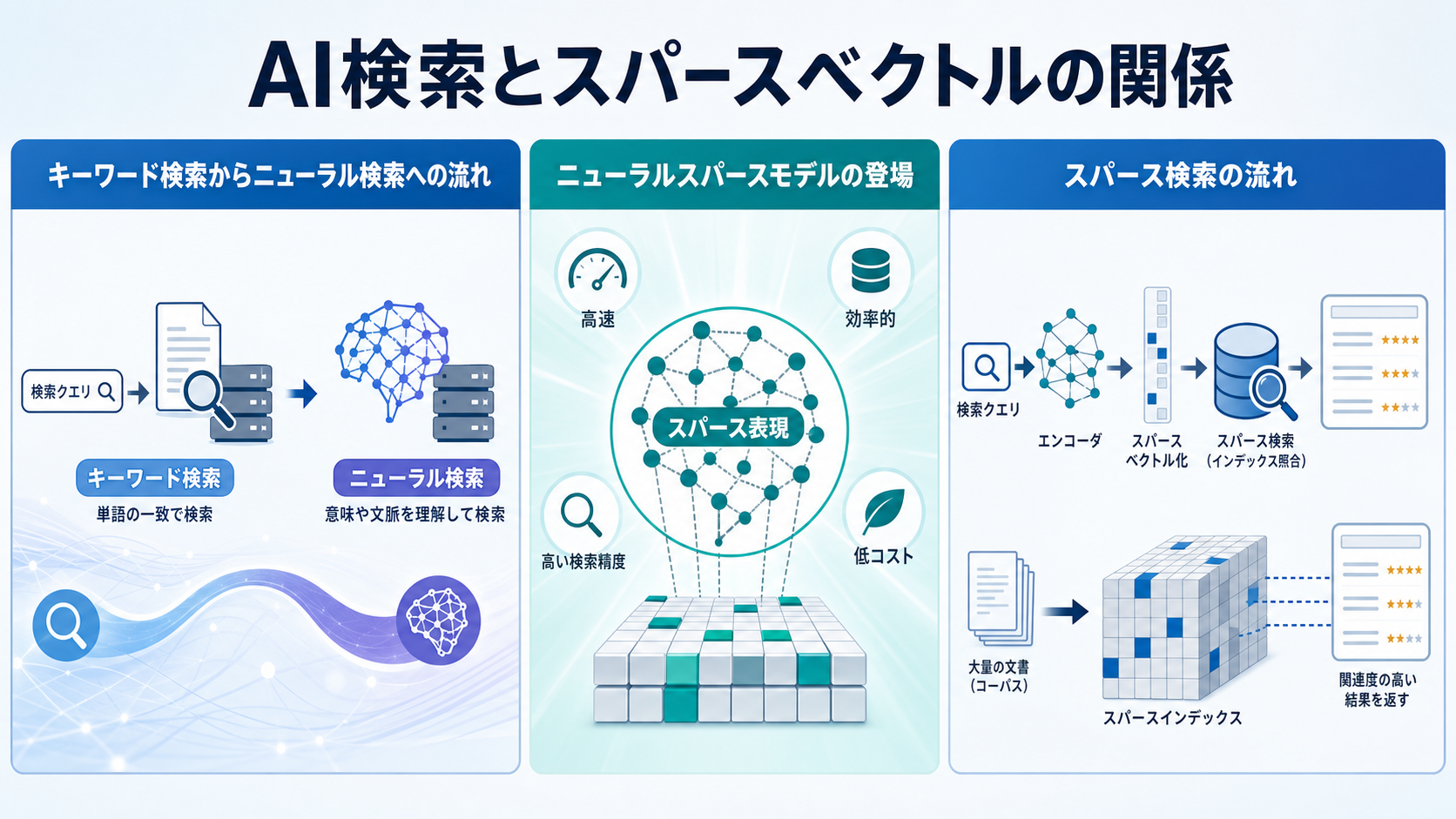
キーワード検索からニューラル検索への流れ
従来の検索エンジンは、BM25に代表されるキーワード一致型の手法が主流でした。これらは語彙ベースで動作するため、クエリと文書に同じ単語が含まれていないとマッチしにくいという弱点があります。
これを補うために登場したのが、Transformerなどの深層学習モデルを使った密ベクトル検索です。文章全体の意味を低次元の埋め込みに変換することで、表現が異なっても意味が近い文書を見つけられるようになりました。
ニューラルスパースモデルの登場
ニューラルスパースモデルは、Transformerの言語理解能力を活かしながら、出力をスパースな語彙空間に投影する新しいアプローチです。SPLADEなどに代表されるこの手法は、クエリや文書に対して「重要な単語」と「その重み」を自動的に推定します。
従来のBM25が単語の出現頻度に基づいていたのに対し、ニューラルスパースモデルは文脈を理解した上で関連語や同義語にも重みを付与できます。これにより、語彙ベースの説明可能性を保ちながら、意味的な拡張も実現しています。
スパース検索の流れ
スパースベクトルを用いた検索は、以下のような流れで実行されます。インデックス構築段階で各文書をスパースベクトルに変換し、検索エンジンの転置インデックスに登録します。
クエリが入力されると、同様にスパースベクトルへ変換し、内積などの類似度計算によって関連文書を高速に取得します。非ゼロ要素のみを扱うため、大規模なコーパスでも高速に動作するのが特徴です。
スパース検索を検討する際のチェックポイントです。
- 専門用語や固有名詞が多いコーパスか
- 検索結果の根拠を説明する必要があるか
- 大規模文書を高速に検索したいか
- 既存のキーワード検索からの移行を検討しているか
これらに当てはまる場合、スパースベクトルの導入によって検索体験を大きく改善できる可能性があります。
ニューラルスパース検索は「古典×AI」のいいとこ取りなんですよ。BM25の延長線上にある進化形と捉えてみてください。
AI検索パートナーズでは、
AIに”選ばれる”ための戦略設計から実行まで支援!
密ベクトルとの違いとハイブリッド検索
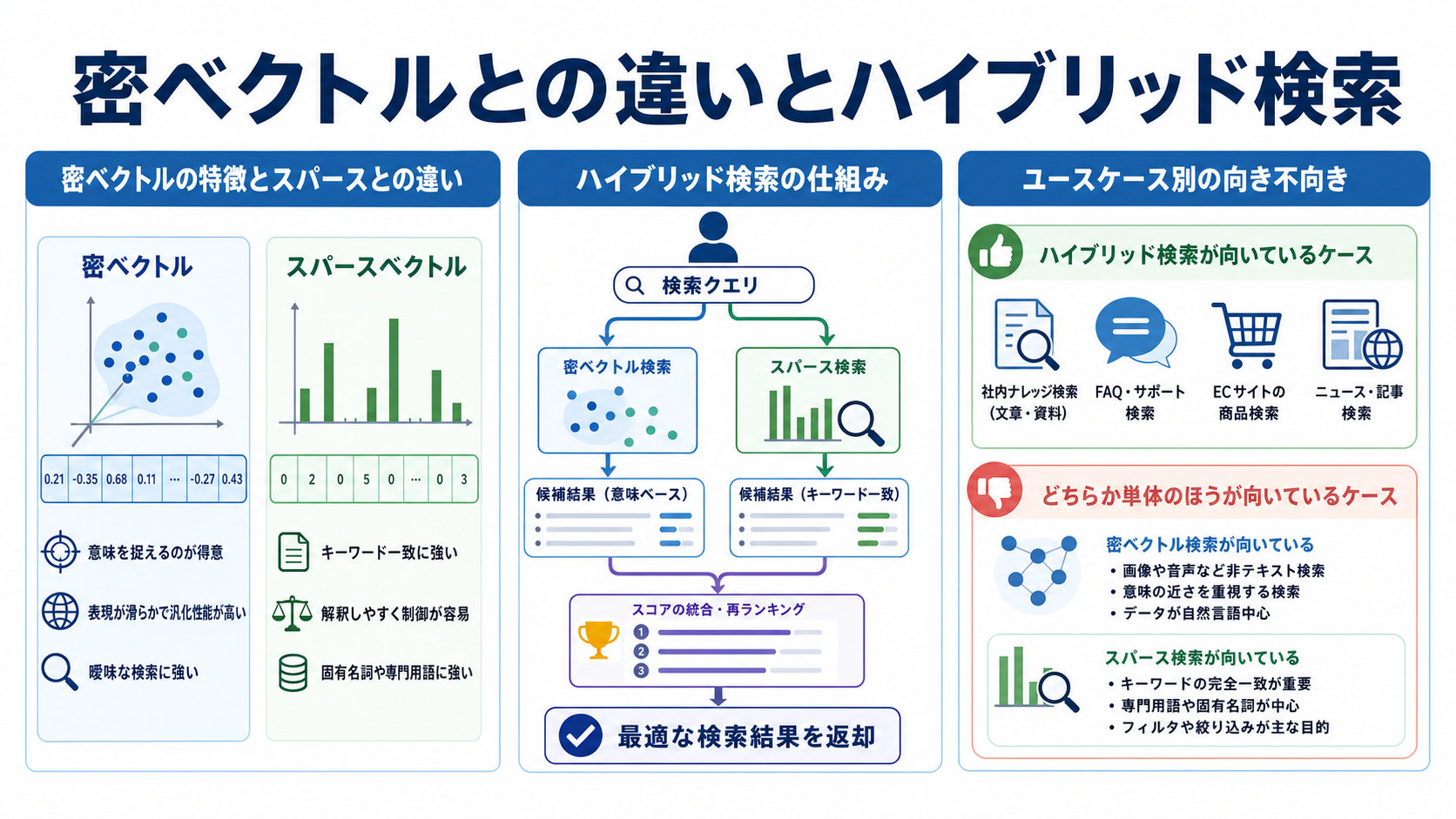
密ベクトルの特徴とスパースとの違い
密ベクトルはBERTなどの事前学習モデルから得られる埋め込みで、文章全体の意味を凝縮した表現です。同義語や言い換えに強く、表面的な語が異なっていても意味が近い文書を見つけられます。
一方、スパースベクトルは語彙レベルで精密にマッチするため、固有名詞や型番、専門用語などのレア語に圧倒的に強いという特性があります。また、どの単語がマッチしたかを可視化できるため、検索結果のチューニングや説明が容易です。
ハイブリッド検索の仕組み
ハイブリッド検索は、スパースと密の両方で検索を行い、スコアを統合して最終結果を出す方式です。代表的にはBM25と密ベクトルの組み合わせ、あるいはニューラルスパースと密の組み合わせが用いられます。
スコア統合の方法には、線形結合やRRF(Reciprocal Rank Fusion)などがあります。これにより、語彙一致の精度と意味理解の柔軟性を両立した検索体験が実現できます。
ユースケース別の向き不向き
用途によって最適な構成は異なります。以下に代表的なシナリオをまとめます。
| ユースケース | 推奨構成 | 理由 |
|---|---|---|
| EC商品検索 | ハイブリッド | 型番一致と意味検索の両立が必要 |
| FAQ検索 | 密ベクトル中心 | 言い換えや意図理解が重要 |
| 社内ナレッジ検索 | ハイブリッド | 専門用語と意味検索の両立 |
| 法務・特許文書 | スパース中心 | 用語の厳密な一致が必須 |
| RAG向け検索 | ハイブリッド | 抜け漏れと意味理解の両立 |
このように、データの性質と検索要件に応じて構成を選ぶことが重要です。
「どっちか一方」ではなく「両方使う」が現代AI検索の王道です。まずはハイブリッド前提で設計してみましょう。
AI検索パートナーズでは、AIに”選ばれる”ための戦略設計から実行まで一気通貫で支援!
AI検索パートナーズでは、AI検索の専門知識と支援実績を持つ専任コンサルタントが、AIに“引用される・選ばれる”ための戦略設計からコンテンツ最適化、効果測定・改善まで一気通貫でご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
スパースベクトルの実装と技術選定
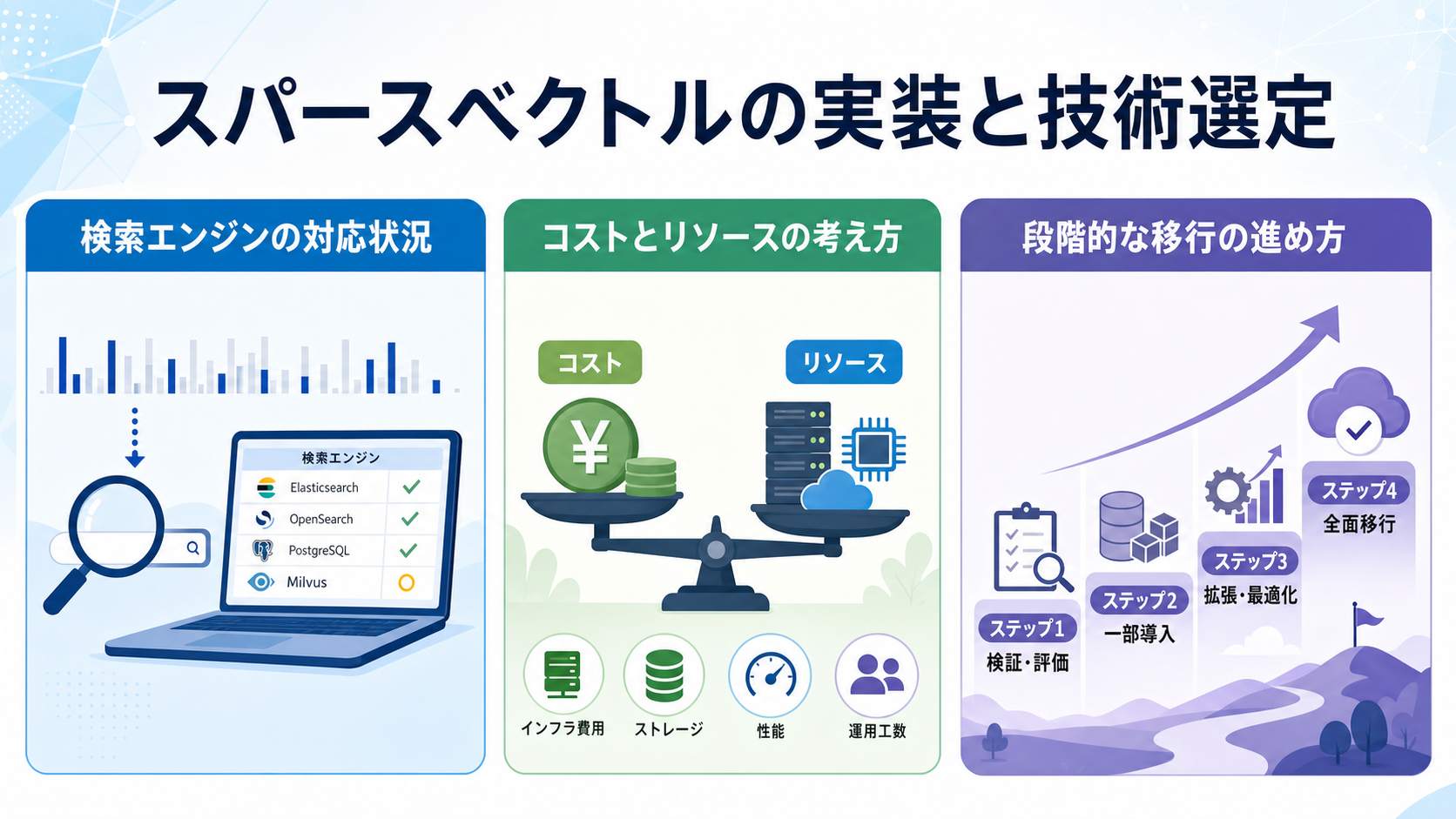
検索エンジンの対応状況
ElasticsearchやOpenSearchは、スパースベクトルフィールドや密ベクトルフィールドを併用できる機能を提供しており、ハイブリッド検索の構築に適しています。BM25との組み合わせも自然に行えます。
ベクトルデータベース専用のサービスでも、スパース・密の両対応やハイブリッドランキングをサポートする動きが広がっています。技術選定時は、自社のクラウド戦略や既存スタックとの親和性も考慮するとよいでしょう。
コストとリソースの考え方
スパースベクトルは転置インデックスとの相性がよく、大規模コーパスでも比較的軽量に動作します。一方、ニューラルスパースモデルを使う場合は、文書のエンコードに推論コストがかかる点に注意が必要です。
密ベクトルと比較すると、推論コスト自体は同程度ですが、インデックス側の構造が異なるため、運用設計やキャパシティプランニングは別途検討する必要があります。
段階的な移行の進め方
既存のBM25ベースのシステムからスパース/ハイブリッドへ移行する場合は、段階的なアプローチが現実的です。まずはBM25に密ベクトルを追加するハイブリッド構成から始めるのが一般的とされています。
その後、必要に応じてニューラルスパースモデルへの置き換えや、用途ごとの最適化を進めるという流れが取り組みやすいでしょう。最初から全面刷新を狙うのではなく、A/Bテストで効果を確認しながら拡張するのが安全です。
段階的移行の典型的なステップです。
- 現状のBM25検索の課題を整理する
- 密ベクトルを追加してハイブリッド化する
- 必要に応じてニューラルスパースを導入する
- 用途別にチューニングと評価を繰り返す
このような段階的な進め方なら、リスクを抑えながら検索体験を改善できます。
いきなり全面刷新は避けて、まずはハイブリッドから始めるのが堅実なんですよ。小さく試して効果を測りましょう。
ビジネス活用と導入効果
RAGや社内検索での活用
RAG(検索拡張生成)では、LLMに渡す参照文書の質が回答精度を大きく左右します。スパースベクトルを組み込むことで、専門用語や固有名詞を含むクエリでも、関連性の高い文書を確実に取得できます。
社内ナレッジ検索では、製品名や型番、社内特有の略語などレア語が多いため、スパースベクトルの精密マッチングが特に効果を発揮します。密ベクトルと組み合わせることで、表現ゆれにも対応した堅牢な検索が実現できます。
導入で期待できる効果
スパースベクトル導入の主な効果としては、検索精度の向上、長文・専門文書での検索性向上、説明可能性によるチューニング容易性などが挙げられます。特に、なぜその文書がヒットしたかを語彙レベルで確認できる点は、運用上の大きな利点です。
また、BM25からの自然な進化として位置づけられるため、既存のキーワード検索の知見を活かしながら導入を進められるのも実務上のメリットといえるでしょう。
よくある誤解と正しい理解
「ニューラル=すべて密ベクトル」「スパース=古い技術」という誤解は根強く存在します。しかし実際には、ニューラルスパースモデルのように、深層学習を用いたスパース表現も活発に研究・実装されています。
また、「密ベクトルだけあれば十分」というのも実務上は誤りで、レア語や厳密な一致が必要な場面では密ベクトルの弱点が顕在化します。スパースと密はどちらかではなく、補完関係にあると捉えるのが正しい理解です。
| 誤解 | 正しい理解 |
|---|---|
| スパースは古い技術 | ニューラルスパースとして進化し続けている |
| 密ベクトルだけで十分 | レア語や厳密一致では密が苦手な領域がある |
| BM25は時代遅れ | 多くのハイブリッド構成で現役活用されている |
| 導入はコストが高い | 段階的に導入すればリスクを抑えられる |
こうした誤解を解消し、適切な技術選定につなげることが重要です。
スパースと密は「対立」ではなく「協力」関係です。RAGや社内検索の精度を底上げできるはずですよ!
よくある質問
- スパースベクトルと密ベクトルはどちらを選ぶべきですか
-
どちらか一方ではなく、両方を組み合わせるハイブリッド検索が有効とされています。専門用語や固有名詞が多いデータならスパースの比重を高め、意味的な検索が重要ならば密ベクトルを活用するなど、用途に応じた重み付けで構成するのが現実的です。
- BM25とニューラルスパースモデルの違いは何ですか
-
BM25は単語の出現頻度と希少性に基づく統計的手法ですが、ニューラルスパースモデルはTransformerなどで文脈を理解した上で重要な単語と重みを推定します。後者は関連語や同義語にも自動的に重みを付与できる点で進化しています。
- RAGにスパースベクトルを導入するメリットは何ですか
-
RAGでは参照文書の質が回答精度を左右するため、専門用語や固有名詞を確実に拾えるスパースベクトルが有効です。密ベクトルだけでは取りこぼしがちなレア語クエリにも対応でき、結果としてLLMの回答の正確性向上が期待できます。
- 既存のキーワード検索からの移行は難しいですか
-
いきなり全面刷新する必要はなく、まずはBM25に密ベクトルを追加するハイブリッド構成から始めるのが一般的です。効果を測定しながら段階的にニューラルスパースなどを導入することで、リスクを抑えた移行が可能になります。
まとめ
スパースベクトルは、語彙レベルで精密にマッチする疎な表現で、レア語や専門用語に強く説明可能性も高いという特徴があります。AI検索の文脈では、BM25などの古典手法を進化させたニューラルスパースモデルが登場し、再び注目を集めています。
密ベクトルとの違いを理解し、両者を組み合わせるハイブリッド検索を活用することで、語彙一致と意味理解を両立した検索体験が実現できます。RAGや社内検索、EC検索など、ユースケースに応じた構成を選ぶことが重要です。
まずは自社の検索課題を整理し、段階的にスパース/密/ハイブリッドの導入を検討してみてはいかがでしょうか。検索精度の向上が、AIプロダクトの価値そのものを押し上げてくれるはずです。

