

AI検索やRAG(検索拡張生成)の導入が進む中で、「検索結果の関連性が低い」「生成AIの回答が的外れになる」といった課題に直面していませんか。その解決策として注目されているのが「リランキング(再ランキング)」という技術です。本記事では、リランキングの基本概念からAI検索における重要性、具体的な実装方法、評価指標までを体系的に解説します。検索精度を飛躍的に向上させ、ユーザー体験と生成AIの信頼性を高めるための実践的な知識を提供します。
- リランキングの基本概念とAI検索での役割
リランキングは一次検索で取得した候補を文脈や意図に合わせて再順位付けする技術で、AI検索やRAGの回答精度を大きく向上させます。
- 代表的なリランキング手法と使い分け
クロスエンコーダ、学習ベース、LLM活用など複数の方式があり、コスト・精度・速度のバランスで選定することが重要です。
- 導入手順と精度評価の進め方
候補取得から再ランキング、生成回答までのパイプライン構築と、nDCGやMRRなどの指標を用いた継続的な評価が成功の鍵となります。
リランキングとは何か
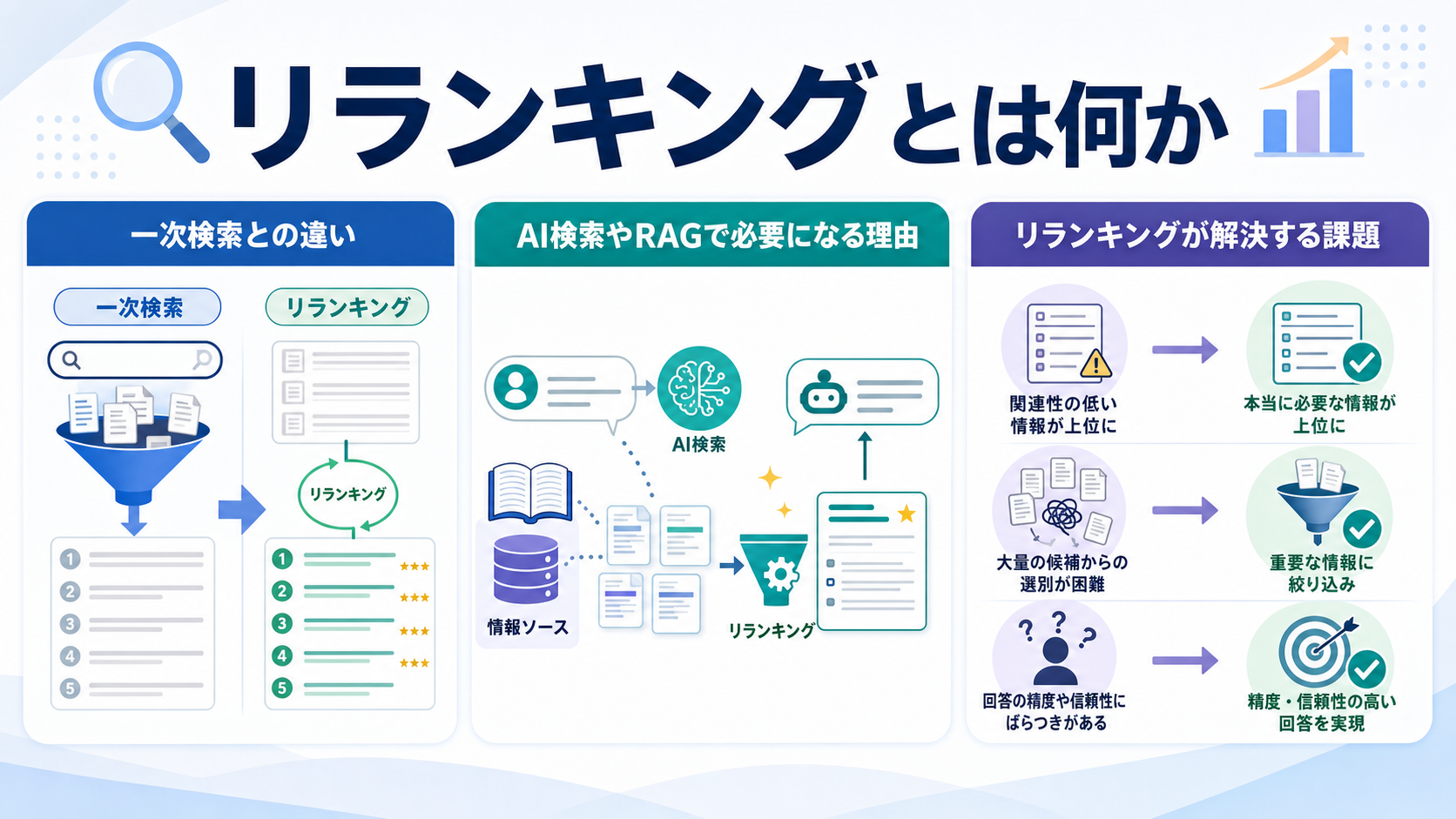
一次検索との違い
一次検索は数百万〜数億の文書から高速に候補を絞り込む処理であり、BM25やベクトル類似度などの軽量な手法が用いられます。一方リランキングは数十〜数百件程度の候補に絞った後で、クエリと文書の意味的関係を深く分析して順位を決め直す処理です。
つまり一次検索が「広く浅く」、リランキングが「狭く深く」という役割分担になります。両者を組み合わせることで、計算コストを抑えつつ高精度な検索体験を実現できるのです。
AI検索やRAGで必要になる理由
RAGでは、検索で取得した文書を生成AIに渡して回答を作成します。このとき検索結果の質が低いと、生成AIは誤った情報や関連性の低い情報をもとに回答してしまうため、ハルシネーション(誤情報生成)のリスクが高まります。
リランキングを導入することで、生成AIに渡すコンテキストの質が劇的に向上し、回答の正確性と信頼性が高まります。特に企業の社内検索やカスタマーサポートでは、この精度差がユーザー満足度に直結します。
リランキングが解決する課題
ベクトル検索だけでは、意味的に近いけれども質問に直接答えない文書が上位に来てしまうことがあります。たとえば「返品の手順」を聞いたのに「返品ポリシーの概要」が上位に来るようなケースです。
リランキングは、クエリへの直接性、最新性、信頼性などを総合的に判断し、本当に「答え」となる文書を上位に配置します。これにより、ユーザーが少ない手数で求める情報にたどり着ける検索体験を構築できます。
下表は一次検索とリランキングの違いを整理したものです。両者の役割を理解することで、自社システムのどこを改善すべきかが見えてきます。
| 項目 | 一次検索 | リランキング |
|---|---|---|
| 処理対象数 | 数百万〜数億件 | 数十〜数百件 |
| 処理速度 | 高速(ミリ秒単位) | やや低速(数百ms〜数秒) |
| 主な手法 | BM25、ベクトル検索 | クロスエンコーダ、LLM |
| 重視する観点 | 網羅性・速度 | 精度・文脈一致 |

リランキングは一次検索の「足りない精度」を補う重要な工程なんです。役割を分けて考えると、改善ポイントが見えてきますよ。
AI検索におけるリランキングの仕組み
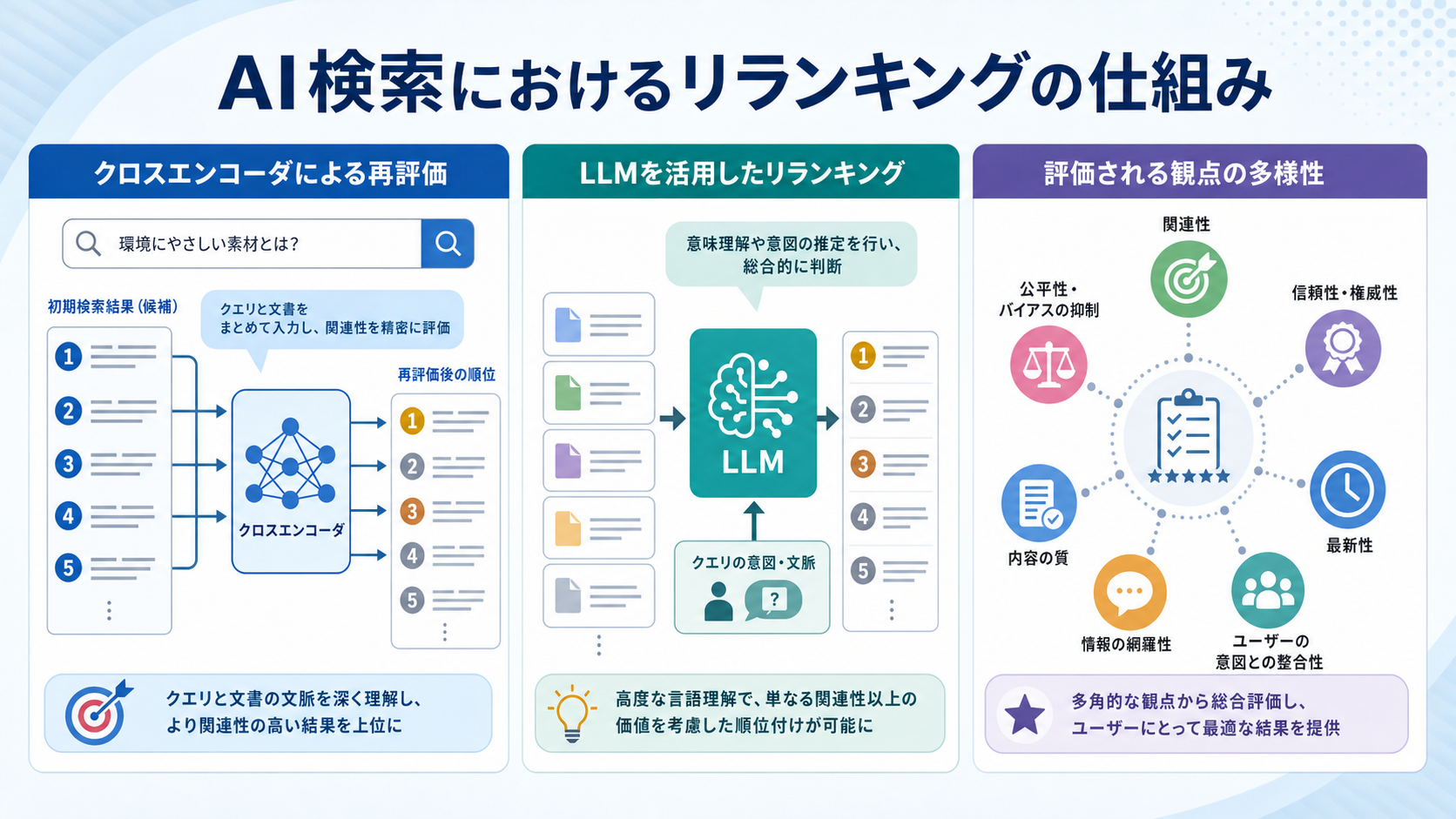
クロスエンコーダによる再評価
クロスエンコーダは、クエリと文書を1つの入力として同時にモデルに渡し、関連度スコアを出力する手法です。ベクトル検索で使われるバイエンコーダよりも文脈理解が深く、クエリと文書の細かな対応関係を捉えられるのが特徴です。
処理コストは高いものの、数十〜数百件の候補に絞り込んだ後に適用することで、実用的な速度と高精度を両立できます。多くの商用リランキングAPIがこの方式を採用しています。
LLMを活用したリランキング
近年は大規模言語モデル(LLM)を用いたリランキングも普及してきました。LLMにクエリと候補文書を渡し、関連度を判定させたり、順位を直接生成させたりする方式です。
LLMリランキングは、複雑な意図理解や多段階推論を要するクエリで高い精度を発揮します。一方でコストとレイテンシが課題となるため、重要なクエリに限定して適用するなどの工夫が求められます。
評価される観点の多様性
リランキングでは単純な類似度だけでなく、複数の観点が総合的に評価されます。たとえば質問への直接的な回答性、情報の最新性、ソースの信頼性、文書の網羅性などが挙げられます。
これらの観点を組み合わせることで、ユーザーの真のニーズに応える検索結果を実現できます。業務領域や用途に応じて、重視する観点を調整することも重要です。
リランキングで評価される代表的な観点を以下に整理しました。自社の検索要件と照らし合わせて、どの観点を重視すべきか検討する際の参考になります。
リランキングで評価すべき主な観点
- クエリへの直接的な回答性(質問に直接答えているか)
- 意味的・文脈的な一致度
- 情報の最新性・鮮度
- ソースの信頼性・権威性
- 文書の網羅性・具体性
多角的な観点で評価することが、AI検索の精度を一段引き上げるコツです。自社の用途に合わせて重み付けを工夫してみましょう。
AI検索パートナーズでは、
AIに”選ばれる”ための戦略設計から実行まで支援!
リランキングの代表的な手法
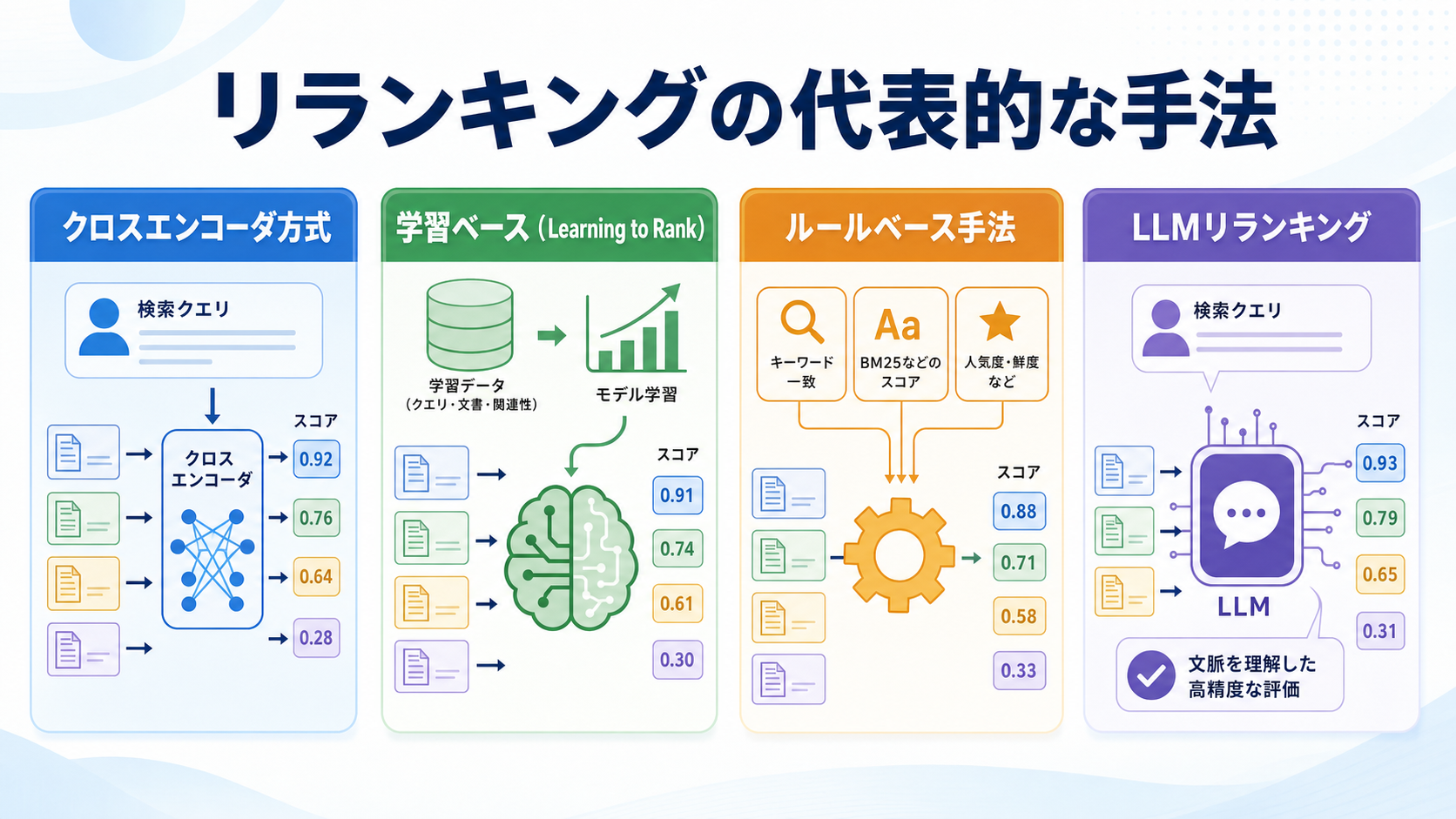
クロスエンコーダ方式
クロスエンコーダ方式は、事前学習済みのTransformerモデルを使い、クエリと文書のペアを入力して関連度スコアを出力します。商用のリランキングAPIやオープンソースモデルが充実しており、比較的導入しやすい選択肢として広く採用されています。
精度と速度のバランスが良く、多くのRAGシステムで標準的に使われています。GPU環境を用意できるか、API経由で使うかで運用設計が変わります。
学習ベース(Learning to Rank)
Learning to Rank(LTR)は、ユーザーのクリックログや評価データを使って、ランキングモデルを教師あり学習する手法です。自社のユーザー行動に最適化されたランキングを実現できます。
導入には十分なログデータと機械学習の知見が必要ですが、ドメイン特化の精度向上が期待できます。検索ボリュームが大きく、継続的に改善できる体制がある場合に適しています。
ルールベース手法
ルールベース手法は、最新性や信頼性、特定キーワードの出現などを基準にスコアを調整する方式です。シンプルで透明性が高く、ビジネス要件を直接反映しやすい利点があります。
機械学習モデルと組み合わせて使うことで、業務上重要な制約(新着優先、特定カテゴリ優先など)を確実に反映できます。導入コストが低い点も魅力です。
LLMリランキング
LLMリランキングは、GPTなどの大規模言語モデルにプロンプトでランキングを依頼する手法です。複雑な意図や曖昧なクエリにも対応でき、最も柔軟性が高い方式といえます。
ただしAPIコストとレイテンシが高いため、ハイブリッド構成や重要クエリ限定での使用が一般的です。プロンプト設計の工夫次第で精度が大きく変わります。
各手法の特徴を比較した表を以下に示します。自社の要件と照らし合わせて最適な方式を検討する際にご活用ください。
| 手法 | 精度 | コスト | 速度 | 適した用途 |
|---|---|---|---|---|
| クロスエンコーダ | 高い | 中 | 中 | 汎用的なRAG・検索 |
| 学習ベース(LTR) | 非常に高い | 高(初期) | 速い | 大規模・ドメイン特化 |
| ルールベース | 中 | 低 | 非常に速い | 制約反映・補助 |
| LLMリランキング | 非常に高い | 高 | 遅い | 複雑な意図理解 |
手法は一つに絞らず、組み合わせて使うのが効果的ですよ。まずはクロスエンコーダから試してみるのがおすすめです。
AI検索パートナーズでは、AIに”選ばれる”ための戦略設計から実行まで一気通貫で支援!
AI検索パートナーズでは、AI検索の専門知識と支援実績を持つ専任コンサルタントが、AIに“引用される・選ばれる”ための戦略設計からコンテンツ最適化、効果測定・改善まで一気通貫でご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
リランキングの導入手順
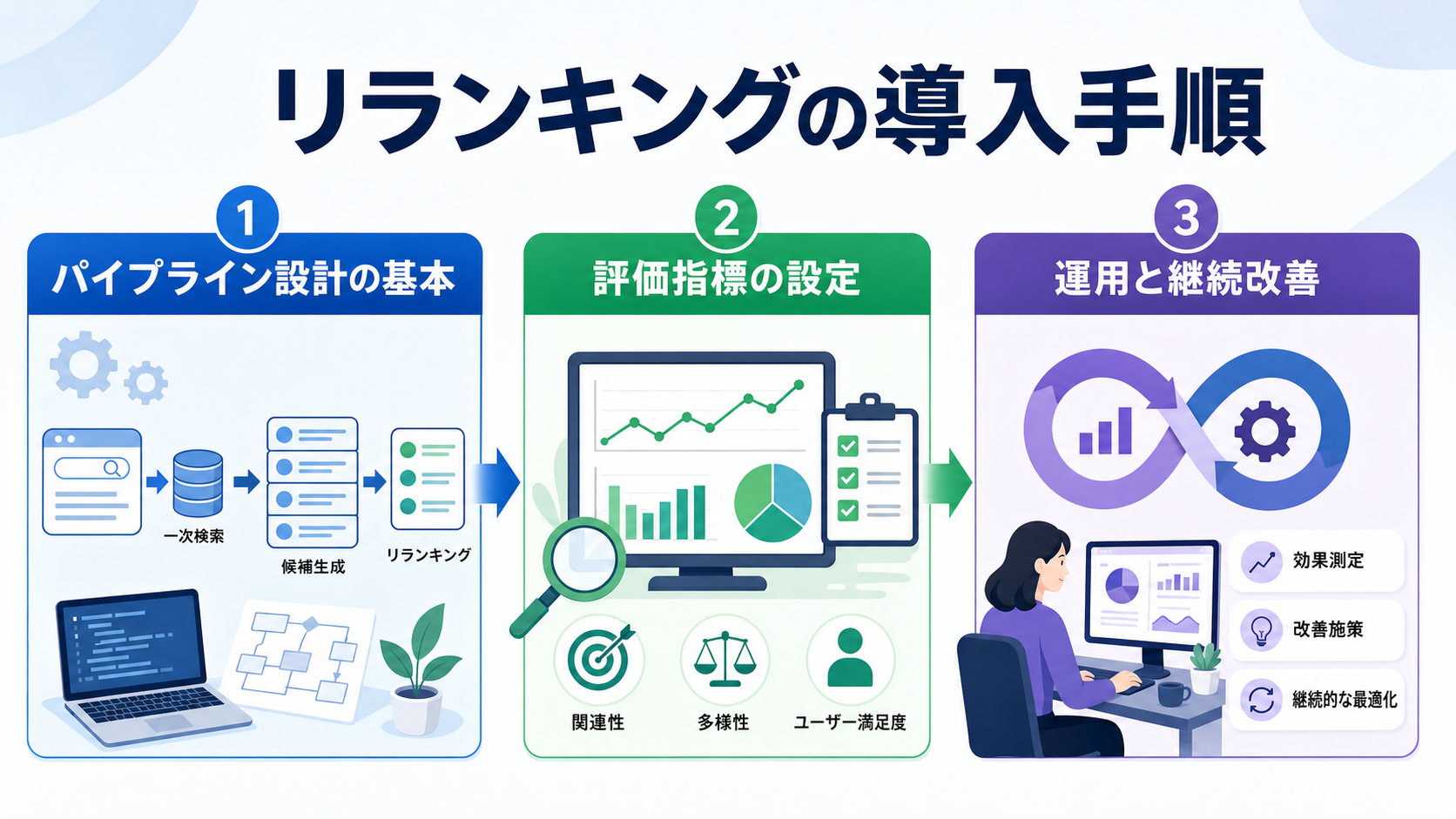
パイプライン設計の基本
標準的なRAGパイプラインは「クエリ解析→一次検索→リランキング→回答生成」の流れになります。一次検索で取得する候補数とリランキング後に残す件数のバランスが、精度と速度を決める重要なパラメータです。
一般的には一次検索で50〜200件を取得し、リランキング後に5〜20件を生成AIに渡す構成が多く採用されています。用途や文書量に応じて調整しましょう。
評価指標の設定
導入効果を測るには、定量的な評価指標を事前に決めておく必要があります。代表的な指標としてnDCG(正規化割引累積利得)、MRR(平均逆順位)、Recall@K、Precision@Kなどがあります。
オフライン評価用のテストセットを構築し、リランキング有無で指標を比較することで、効果を客観的に検証できます。実ユーザーのフィードバックを取り込むA/Bテストも有効です。
運用と継続改善
リランキングは導入して終わりではなく、継続的な調整が品質維持の鍵となります。ユーザーの検索ログやクリック率を分析し、候補数や閾値、モデルのバージョンを定期的に見直しましょう。
また、業務領域の変化や文書の更新に応じて、再学習やプロンプト調整も必要になります。MLOpsの観点を取り入れた運用体制が望ましいといえます。
導入時に確認すべきポイントを以下のチェックリストにまとめました。プロジェクトを進める際の指針としてご活用ください。
リランキング導入時のチェックリスト
- 一次検索の取得件数とリランキング後の残件数を設計したか
- 評価用のテストデータセットを準備したか
- nDCGやMRRなど評価指標を決めたか
- レイテンシ要件とコスト上限を明確化したか
- A/Bテストやログ分析の仕組みを整えたか
- 継続的なモデル更新の運用フローを設計したか
導入後の運用改善こそがリランキング成功の本質です。小さく始めて、データを見ながら育てていきましょう。
リランキング導入の効果と注意点
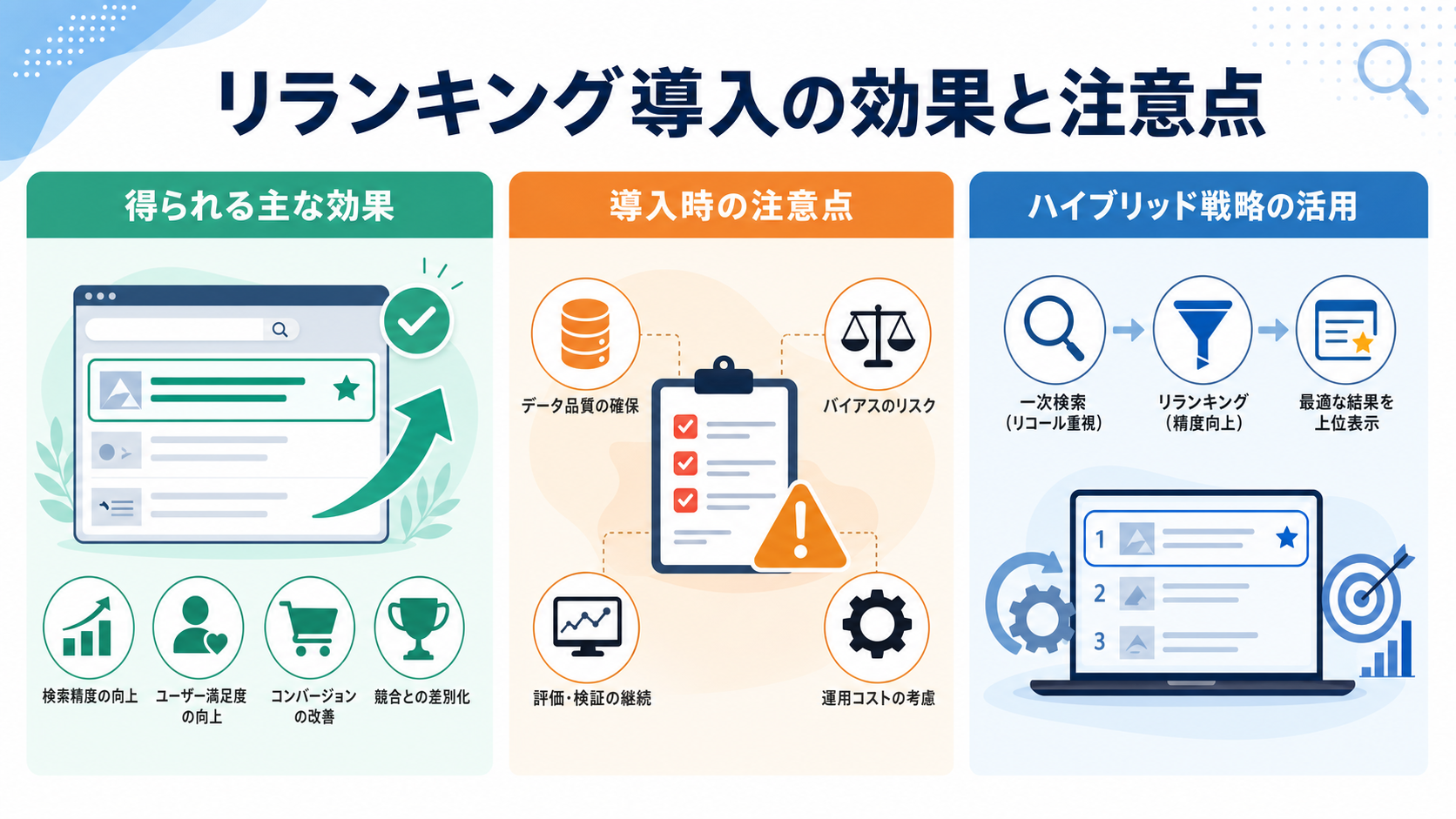
得られる主な効果
リランキング導入の最大の効果は、生成AIに渡すコンテキストの質が向上し、回答精度が安定することです。ユーザーが求める情報に少ない手数でたどり着けるようになり、問い合わせ削減や満足度向上に直結します。
また、ハルシネーションの発生率が下がり、生成AIへの信頼性が高まることも重要な効果です。社内ナレッジ検索やカスタマーサポートで特に効果が顕著といわれています。
導入時の注意点
リランキングはコストとレイテンシの増加を伴います。特にLLMリランキングでは1クエリあたりの処理時間が数秒単位になることもあるため、ユーザー体験を損なわない設計が必要です。
また、過度なチューニングは特定パターンへの過学習を招き、汎用性を損なう恐れがあります。テストデータの多様性確保と、定期的な見直しが欠かせません。
ハイブリッド戦略の活用
実務では複数の手法を組み合わせるハイブリッド戦略が効果的です。たとえばクロスエンコーダで全体を再ランキングしつつ、ルールベースで最新性や信頼性を補正するといった構成です。
用途やコスト制約に応じて柔軟に組み合わせることで、最適なバランスを実現できます。段階的に高度な手法を取り入れていくアプローチが現実的でしょう。
導入効果と注意点を整理した比較表を以下に示します。期待できる成果と対処すべき課題を併せて把握しておくことが重要です。
| 観点 | 期待できる効果 | 注意すべき点 |
|---|---|---|
| 回答精度 | 関連性の高い情報が上位に | 過学習による汎用性低下 |
| ユーザー体験 | 少ない手数で目的達成 | レイテンシ増加への配慮 |
| 運用コスト | 問い合わせ削減・効率化 | API利用料・GPU費用の増加 |
| 信頼性 | ハルシネーション低減 | 継続的なモデル更新が必要 |
効果と課題を両方理解した上で導入すれば、リランキングは強力な武器になります。バランス感覚を大切にしましょう。
よくある質問
- リランキングはすべてのAI検索で必要ですか
-
必須ではありませんが、回答精度を重視するRAGや業務システムでは導入効果が大きいといわれています。検索対象の文書数が多く、ユーザーの質問が多様な場合には特に有効です。一方、検索対象が限定的で一次検索だけで十分な精度が出る場合は、コスト面から導入を見送る選択肢もあります。
- リランキング導入で速度はどれくらい遅くなりますか
-
採用する手法と候補数によりますが、クロスエンコーダで数百ms、LLMリランキングで数秒程度の追加レイテンシが一般的です。候補数を絞り込む、軽量モデルを使う、キャッシュを活用するなどの工夫で、ユーザー体験を損なわない範囲に抑えることができます。
- リランキングの効果はどう測定すればよいですか
-
nDCG、MRR、Recall@K、Precision@Kなどの指標を使ったオフライン評価が基本です。テストデータセットを事前に準備し、リランキング有無で比較します。さらに実ユーザーのクリック率や満足度を測るA/Bテストを併用することで、実環境での効果を客観的に検証できます。
- 小規模なプロジェクトでも導入する価値はありますか
-
小規模でも、回答品質がビジネス価値に直結するなら導入する意義はあります。最近はAPI型のリランキングサービスが充実しており、初期投資を抑えて試せる環境が整っています。まずは小さく試して効果を確認し、段階的に拡張していくアプローチが現実的でしょう。
まとめ
リランキングは、AI検索やRAGにおいて検索精度を飛躍的に高めるための重要な技術です。一次検索で広く候補を取得し、リランキングで文脈や意図に基づき再順位付けすることで、生成AIに渡すコンテキストの質が向上します。
クロスエンコーダ、学習ベース、ルールベース、LLM活用など、複数の手法を用途に応じて使い分けることが成功の鍵です。コストとレイテンシのトレードオフを意識しつつ、評価指標を用いた継続的な改善を進めましょう。
適切なリランキング導入により、ユーザーは少ない手数で正しい情報にたどり着き、業務効率化や満足度向上、生成AIの信頼性向上といった多面的な成果を得られます。まずは小さく試し、データを見ながら育てていく姿勢が成功への近道です。










