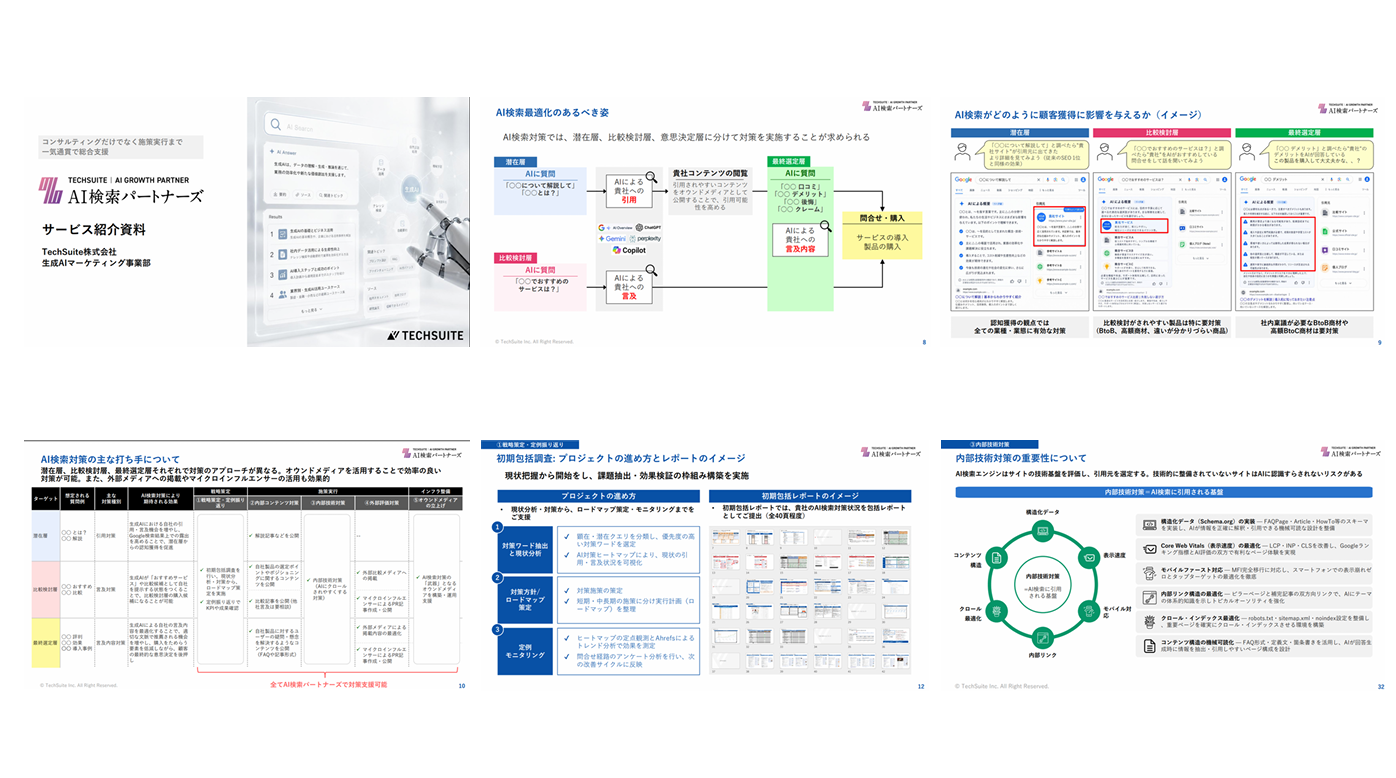
AIや検索エンジンの進化に伴い、「ベクトル検索」や「セマンティック検索」という言葉を耳にする機会が増えています。従来のキーワード一致型の検索とは異なり、文章の「意味」を理解して検索結果を返す技術は、情報検索の精度を大きく向上させました。さらに近年では、ChatGPTをはじめとするLLM(大規模言語モデル)がユーザーの情報収集手段として台頭し、LLMO(LLM最適化)やGEO(生成エンジン最適化)への関心も高まっています。本記事では、ベクトル検索とセマンティック検索の基本的な仕組みから両者の違い、そしてLLMO対策への具体的な活用法までをわかりやすく解説します。
- ベクトル検索の仕組みと特徴
ベクトル検索はテキストを数値ベクトルに変換し、意味的な近さをもとに検索結果を返す技術です。
- セマンティック検索との違い
セマンティック検索は「意味を理解する検索」の総称であり、ベクトル検索はその中核技術の一つという関係にあります。
- LLMO対策への具体的な活用法
ベクトル検索やセマンティック検索の仕組みを理解することで、AI検索に引用されやすいコンテンツ設計が可能になります。
ベクトル検索の仕組みとは

埋め込みベクトルの生成方法
ベクトル検索の第一歩は、テキストデータをEmbeddingモデルによって数百〜数千次元の数値ベクトルに変換する工程です。この変換処理を「埋め込み(Embedding)」と呼びます。たとえば「犬が公園で遊んでいる」という文と「ペットが広場で走り回っている」という文は、キーワードは異なっていても、ベクトル空間上では近い位置にマッピングされます。
Embeddingモデルには、OpenAIのtext-embedding-adaやGoogleのGeckoなど複数の選択肢があります。モデルの性能によってベクトル検索の精度が大きく左右されるため、用途に合ったモデル選定が重要です。
類似度計算の代表的な手法
生成されたベクトル同士の「近さ」を測る方法として、コサイン類似度やユークリッド距離などの手法が用いられます。特にコサイン類似度は、ベクトルの方向の近さを0から1の値で表すため、テキスト検索の類似度指標として広く採用されています。
以下の表は、代表的な類似度計算手法の特徴をまとめたものです。
| 計算手法 | 特徴 | 主な用途 |
|---|---|---|
| コサイン類似度 | ベクトルの方向の近さを測定 | テキスト検索、推薦システム |
| ユークリッド距離 | ベクトル間の直線距離を測定 | 画像検索、クラスタリング |
| 内積 | ベクトルの大きさと方向を考慮 | 大規模検索システム |
どの手法を選ぶかはデータの性質や検索の目的によって異なります。テキストベースのベクトル検索では、コサイン類似度が最も一般的な選択肢です。
ベクトルデータベースの役割
大量のベクトルデータを効率的に格納・検索するために利用されるのが、ベクトルデータベースです。代表的なものとしてPinecone、Weaviate、Milvus、Qdrantなどがあります。これらのデータベースは、近似最近傍探索(ANN)アルゴリズムを活用し、膨大なベクトルの中から高速に類似ベクトルを検索できます。
ベクトルデータベースは、RAG(検索拡張生成)の構築においても不可欠な基盤技術として注目されています。RAGではユーザーの質問に関連する情報をベクトル検索で取得し、その情報をLLMに渡して回答を生成する仕組みが採用されています。

ベクトル検索は「意味で探す検索」の土台となる技術です。Embeddingと類似度計算の組み合わせをまず押さえておきましょう。
セマンティック検索の概要

自然言語理解の技術基盤
セマンティック検索の根幹にあるのは、自然言語処理(NLP)技術です。特にTransformerアーキテクチャをベースとしたBERTやGPTなどの言語モデルが、文脈を踏まえた意味理解を実現しています。
セマンティック検索では、「りんご」という単語が果物を指すのかIT企業を指すのかを、前後の文脈から判別できます。この文脈理解能力により、曖昧な検索クエリにも的確な結果を返すことが可能になりました。
キーワード検索との違い
従来のキーワード検索は、TF-IDFやBM25などのアルゴリズムをベースに、検索クエリとドキュメント間の単語の一致度で関連性を判定していました。そのため、同じ意味でも異なる表現を使っていると検索にヒットしないという課題がありました。
以下の表で、キーワード検索とセマンティック検索の主な違いを確認できます。
| 比較項目 | キーワード検索 | セマンティック検索 |
|---|---|---|
| マッチング方式 | 文字列の一致 | 意味の類似度 |
| 同義語への対応 | 対応が困難 | 自動的に考慮 |
| 文脈理解 | なし | 前後の文脈を解析 |
| 検索精度 | クエリの表現に依存 | 意図を汲み取り高精度 |
セマンティック検索はキーワード検索の弱点を補い、ユーザーの「本当に知りたいこと」に近づける技術と言えます。
ナレッジグラフとの連携
セマンティック検索の精度をさらに高める要素として、ナレッジグラフがあります。ナレッジグラフは、エンティティ(人物、場所、概念など)とその関係性をグラフ構造で表現したデータベースです。
Googleの検索エンジンはナレッジグラフを活用し、検索クエリに含まれるエンティティの関係性を理解した上で検索結果を表示しています。たとえば「東京タワーの高さ」と検索すれば、「東京タワー」というエンティティの属性情報から直接回答を返すことができます。
セマンティック検索は「意味を理解する検索」の総称であり、ベクトル検索やナレッジグラフなど複数の技術が組み合わさって成り立っています。
AI検索パートナーズでは、
AIに”選ばれる”ための戦略設計から実行まで支援!
ベクトル検索とセマンティック検索の違い

技術と概念の包含関係
セマンティック検索は「意味理解に基づく検索」という目的を表す概念であり、ベクトル検索はその目的を実現する具体的な技術の一つです。セマンティック検索の実現手段には、ベクトル検索のほかにもナレッジグラフやオントロジーなど複数のアプローチが存在します。
たとえるなら、「移動手段」がセマンティック検索で、「自動車」がベクトル検索のような関係です。自動車以外にも電車や自転車があるように、セマンティック検索にもベクトル検索以外の実現方法があります。
適用領域による使い分け
ベクトル検索は、大量の非構造化データ(テキスト、画像、音声など)から類似コンテンツを高速に検索する場面に適しています。一方、セマンティック検索はWeb検索エンジンや社内ナレッジ検索など、ユーザーの意図を深く理解する必要がある場面で活用されています。
以下の表は、それぞれの適用領域を整理したものです。
| 観点 | ベクトル検索 | セマンティック検索 |
|---|---|---|
| 位置づけ | 技術手段 | 検索の概念・目的 |
| 主な適用領域 | RAG、類似画像検索、推薦 | Web検索、FAQ検索、社内検索 |
| 必要なインフラ | ベクトルデータベース | NLPモデル、ナレッジグラフ等 |
| 精度向上の鍵 | Embeddingモデルの品質 | 文脈理解と知識ベースの充実 |
実際のシステムでは、ベクトル検索とキーワード検索を組み合わせた「ハイブリッド検索」が採用されるケースも増えています。双方の強みを活かすことで、セマンティック検索の精度をさらに向上させることが可能です。
ハイブリッド検索の考え方
ハイブリッド検索とは、キーワード検索(BM25など)の結果とベクトル検索の結果を統合するアプローチです。キーワード検索は固有名詞や専門用語の完全一致に強く、ベクトル検索は意味的な類似性の検出に優れています。
ハイブリッド検索を活用すれば、キーワードの正確さとセマンティックな意味理解の両方を兼ね備えた高精度な検索が実現できます。RAGシステムの構築においても、ハイブリッド検索の導入は検索精度の向上に効果的とされています。
ベクトル検索とセマンティック検索の関係を整理するポイント
- セマンティック検索は「概念」、ベクトル検索は「技術手段」
- 両者は対立ではなく包含関係にある
- ハイブリッド検索で双方の強みを活かせる
- 用途に応じた使い分けが精度向上の鍵となる
ベクトル検索はセマンティック検索を支える技術の一つ。対立構造ではなく包含関係として捉えるのが正確です。
AI検索パートナーズでは、AIに”選ばれる”ための戦略設計から実行まで一気通貫で支援!
AI検索パートナーズでは、AI検索の専門知識と支援実績を持つ専任コンサルタントが、AIに“引用される・選ばれる”ための戦略設計からコンテンツ最適化、効果測定・改善まで一気通貫でご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
LLMO対策への活用法

AIに引用されやすい構造
AIが回答を生成する際に引用しやすいのは、結論ファーストで明確な定義文や回答が記載されたコンテンツです。見出しの直下に「〜とは、〜です」のような簡潔な説明文を配置することで、AIがそのテキストを情報源として抽出しやすくなります。
また、FAQ形式や箇条書きで情報を整理することも効果的です。構造化されたデータはAIのパーサーが解釈しやすく、検索結果への引用確率を高めると考えられています。
Embedding品質を高める文章設計
ベクトル検索で自社コンテンツが正しく検出されるには、Embeddingモデルが文章の意味を正確に捉えられるような記述が求められます。具体的には、1つの段落に1つのトピックを明確にまとめ、曖昧な代名詞の多用を避けることが有効です。
段落ごとにトピックを明確にし、主語と述語を省略しない文章は、Embeddingの精度を高めLLMO対策として有効に機能します。
構造化データとメタ情報の整備
JSON-LDを用いたFAQスキーマやHowToスキーマの実装は、AIが情報を構造的に理解するための重要な施策です。構造化データを適切にマークアップすることで、AIがコンテンツの内容を正確に解釈し、回答生成の素材として優先的に取り扱う可能性が高まります。
さらに、メタディスクリプションやalt属性など、従来のSEOで重視されてきたメタ情報も、AI検索エンジンにとっては有用な文脈情報となります。
LLMO対策としてベクトル検索とセマンティック検索を活かすチェックリスト
- 見出し直下に結論ファーストの定義文を配置しているか
- 1段落1トピックで曖昧な代名詞を避けているか
- FAQ形式や箇条書きで情報を構造化しているか
- JSON-LDによる構造化データを実装しているか
- メタディスクリプションを正確かつ簡潔に記述しているか
ベクトル検索の仕組みを知ることが、AIに「見つけてもらえるコンテンツ」を作る第一歩になるでしょう。
ベクトル検索の導入手順

導入ステップの全体像
ベクトル検索の導入は、大きく分けて「データ準備」「Embeddingモデル選定」「ベクトルデータベース構築」「検索ロジック実装」「評価・改善」の5段階で進めます。それぞれの段階で適切な判断を行うことが、検索精度の向上に直結します。
導入の成否を分けるのは、最初のデータ準備とEmbeddingモデルの選定です。ノイズの多いデータやドメインに合わないモデルを使うと、検索精度が大きく低下するため注意が必要です。
以下の表は、各ステップの概要と主な検討事項をまとめたものです。
| ステップ | 概要 | 主な検討事項 |
|---|---|---|
| データ準備 | 検索対象のテキストを収集・整理 | データのクレンジング、チャンク分割 |
| Embeddingモデル選定 | テキストをベクトルに変換するモデルを選ぶ | 多言語対応、ドメイン適合性 |
| ベクトルDB構築 | ベクトルを格納・検索する基盤を構築 | Pinecone、Qdrant等の比較検討 |
| 検索ロジック実装 | クエリ処理から結果返却までのフローを設計 | ハイブリッド検索の導入可否 |
| 評価・改善 | 検索結果の品質を測定し改善を繰り返す | リコール率、精度の定量評価 |
導入後も継続的な評価と改善が欠かせません。特にEmbeddingモデルの更新やデータの追加に合わせて、定期的にベクトルの再生成を行うことが推奨されます。
チャンク分割の重要性
ベクトル検索の精度を左右する要素の一つに、テキストの「チャンク分割」があります。チャンク分割とは、長い文章を適切な単位に区切ってからベクトル化する工程です。チャンクが長すぎると意味が曖昧になり、短すぎると文脈が失われてしまいます。
一般的に、200〜500トークン程度のチャンクサイズが、セマンティック検索において良好な精度を発揮すると言われています。ただし最適なサイズはデータの性質やユースケースによって異なるため、実験を通じて調整することが効果的です。
ベクトル検索導入時の確認ポイント
- 検索対象データのクレンジングは完了しているか
- チャンク分割のサイズは適切に設定されているか
- Embeddingモデルはドメインに適合しているか
- 検索精度の評価指標を事前に定義しているか
導入は5ステップで整理できます。まずはデータ準備とモデル選定から着手してみましょう。
よくある質問
ベクトル検索やセマンティック検索に関して、よく寄せられる質問とその回答をまとめました。
- ベクトル検索とセマンティック検索はどちらを導入すべきですか
-
両者は対立する概念ではなく、ベクトル検索はセマンティック検索を実現する技術の一つです。セマンティックな検索体験を実現したい場合、ベクトル検索の導入がその手段の一つとなります。用途に応じてキーワード検索との組み合わせ(ハイブリッド検索)も検討するのが効果的です。
- ベクトル検索はSEO対策にどう関係しますか
-
直接的なSEOランキング要因ではありませんが、Googleがセマンティック検索を採用していることから、意味的に充実したコンテンツを作ることはSEOにもプラスに働きます。さらにLLMO対策として、AIがベクトル検索で情報を取得する仕組みを理解しておくことは、AI検索時代のコンテンツ戦略に有用です。
- ベクトル検索を導入するにはプログラミングの知識が必要ですか
-
本格的なシステムを構築する場合はPythonなどのプログラミング知識が必要になります。ただし近年では、ノーコードやローコードでベクトル検索を利用できるサービスも増えてきています。まずは自社の要件を整理し、既存のSaaSツールで対応可能かどうかを確認することをおすすめします。
- LLMO対策として最初に取り組むべきことは何ですか
-
まずはコンテンツの構造化から取り組むことをおすすめします。見出し直下に結論を配置し、FAQ形式で情報を整理し、JSON-LDで構造化データをマークアップすることが基本的な施策です。これらはAIが情報を正確に理解し、引用するための土台となります。
まとめ
ベクトル検索は、テキストを数値ベクトルに変換し意味的な類似度で検索結果を返す技術であり、セマンティック検索を実現するための中核的な手段です。セマンティック検索は「意味を理解する検索」の総称であり、ベクトル検索はその一部として位置づけられます。
AI検索エンジンがRAGを通じてコンテンツを取得する仕組みが広がる中、ベクトル検索の理解はLLMO対策に直結します。結論ファーストの文章構成、構造化データの整備、そして1段落1トピックの明確な記述が、AIに引用されやすいコンテンツの基本条件です。
まずは自社コンテンツの構造を見直し、ベクトル検索やセマンティック検索の視点を取り入れた情報設計に取り組んでみてはいかがでしょうか。従来のSEOとAI検索最適化を両立させることで、これからの検索環境においても安定した集客を実現できるはずです。